
내가 만든 자바 코드가 어떤 과정으로 실행되는지 알아보기 위한 "JVM 알아보기" 다섯 번째 포스팅입니다.
이번 포스팅에서는 JVM GC의 여러 유형에 대해 살펴보고, 그 중 G1 GC 에 대해 자세히 알아보겠습니다.
지난 포스팅에서 이야기한 것과 같이 GC 에는 여러 유형이 있다. 그 중 몇 가지를 알아보도록 하자.
Serial GC
직렬 GC
단일 스레드로 작동하는 가장 간단한 GC 다. 따라서 다중 스레드 프로그램에서는 사용하지 않는다.
단일 스레드를 사용하면 여러 스레드 간에 통신 오버헤드가 없기 때문에 효율성이 높다.
Young 영역의 GC 는 지난 포스팅에서 설명한 방식과 같고, Old 영역의 GC 는 Mark-and-Sweep-Compact 알고리즘을 사용한다.
메모리가 적고 CPU 코어의 개수가 적은 간단한 프로그램에 적합하다.
Parallel GC
병렬 GC, Throughput(처리량) GC

Parallel GC 는 Java 8 의 default JVM 이다.
Serial GC 와 알고리즘은 같지만, 다중 스레드로 동작한다는 차이가 있다.
여러 CPU 를 사용하여 처리 속도가 높기 때문에 처리량 GC 라고도 불린다.
대량 데이터 처리, 일괄 처리와 같은 긴 프로세스를 실행하고 긴 STW(Stop-The-World) 가 허용되는 프로그램에 사용된다.
애플리케이션이 최고의 처리량을 달성해야하고, 1초 이상의 일시적인 작업 중지가 허용된다면 이 GC 를 사용한다.
G1 GC
Garbage First GC

G1 GC 는 Java 9 의 default JVM 으로, 다른 GC 들과는 Heap 의 구조가 매우 다르다.
힙을 동일한 크기의 여러 영역(Region)으로 나누고 각 영역에 객체를 할당하며, 영역 별로 GC 를 수행한다.
다른 가비지 컬렉터가 사용하던 Eden, Survivor 등의 세대 별 영역도 동일한 크기의 여러 영역을 사용한다.
Humongous Region 은 하나의 Region 의 50% 이상 크기를 가진 객체에 할당된다.
G1 은 힙 전체에서 살아있는 객체와 가비지를 식별하기 위해 Concurrent Global Marking(동시 글로벌 마킹)을 진행한다.
마킹이 완료되면 회수 가능한 객체, 즉 가비지로 가득 차 있을 가능성이 큰 힙 영역부터 Sweep 을 진행한다.
G1 GC 는 메모리 공간이 큰(힙 크기가 4GB 이상인) 다중 프로세서 시스템 용으로 설계되었다.
영역 별로 GC 를 수행하기 때문에 STW 가 짧아 튜닝이 거의 필요하지 않고, 높은 처리량을 보인다.
G1 에서 사용하는 자료구조
Remember Set(RSet)
힙에는 Region 마다 RSet 가 존재한다.
참조를 가진 객체들이 어느 영역에 있는지 추적하기 위한 자료구조다.
Collection Set(CSet)
GC 에서 수집 될 Region 의 집합이다.
G1 GC 의 프로세스
1. G1 Heap 구조

힙은 여러 Region 으로 나뉜다. 영역의 크기는 JVM 이 결정하는데, 각 영역의 크기는 최소 1MB 부터 최대 32MB 까지 다양하다.
2. G1 Heap 할당

각 Region 은 Eden, Survivor 등의 논리적 영역으로 매핑된다.
3. G1 의 Young GC
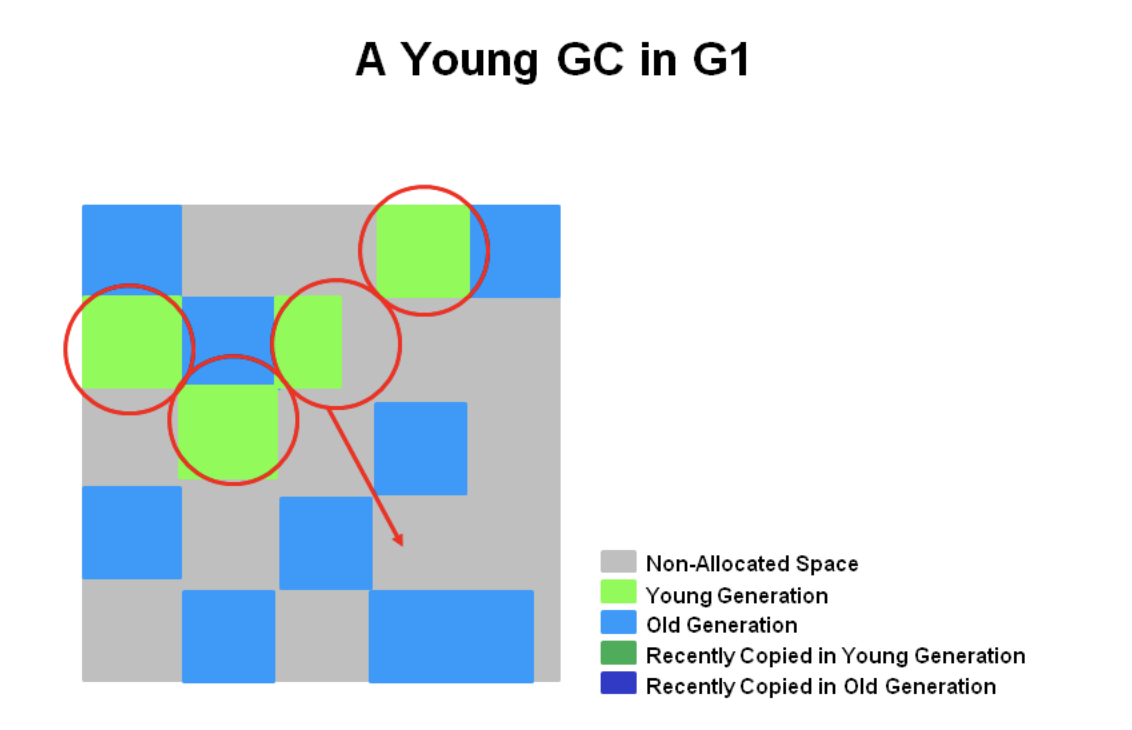

기존의 방식과 같이 Eden 공간이 가득차면 Survivor 공간으로 살아있는 객체를 복사하고, 일정 Age bit 가 넘어가면 Old 영역으로 promotion 된다. 하나 이상의 영역이 하나의 영역으로 복사되면서 압축된다.
Young GC 가 일어날 때는 STW 가 발생하며, 여러 스레드를 사용해서 병렬 수행된다.
4. G1 의 Old GC
G1 의 Old GC 는 다섯 가지 프로세스로 수행된다.
- Initial Mark(STW): Old Region 에 있는 객체에서 참조하는 Survivor Region (Root Region) 을 찾는다.
- Root Region Scanning: 이전 단계(Initial Mark)에서 마크 해두었던 Root Region 을 스캔한다.
- Concurrent Marking: 전체 힙에서 살아있는 객체를 찾고 빈 Region 을 표시한다. 멀티 스레드로 동작하며, 애플리케이션과 동시에 동작한다.

- Remark(STW): 힙에서 살아있는 객체에 마킹을 완료한다. 빈 Region 은 제거된다. 멀티 스레드로 동작하며 SATB(Snapshot-at-the-Beginning) 알고리즘을 사용한다.
- CleanUp(STW): 가비지가 제일 많은 Region 을 정리한다. 해당 Region 은 Young GC 와 동시에 수집되는데, 이를 Mixed GC 라고 한다.

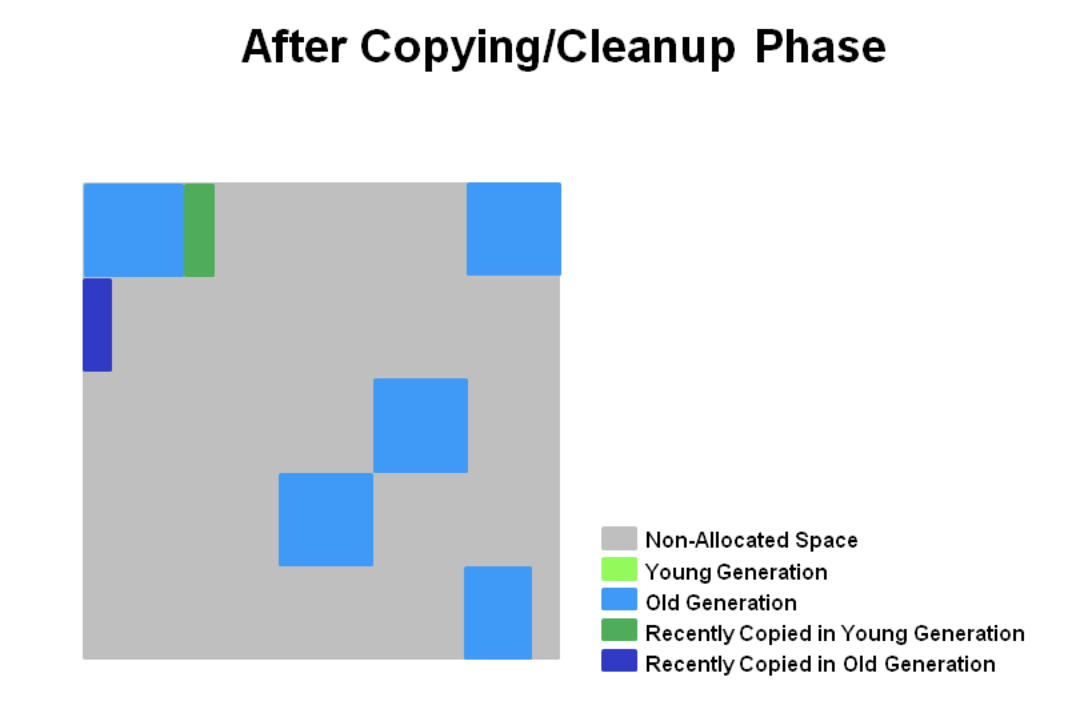
모든 Old GC 의 프로세스가 끝나면 다음과 같이 압축된 상태로 정리된다.
마치며
이번 포스팅에서는 JVM GC 의 몇 가지 유형과 Java 9 의 default GC 인 G1 GC 에 대해서 알아보았습니다.
Region 별로 GC 를 수행하여 STW 시간을 줄였고, 하나 이상의 Region 을 하나로 압축하면서 파편화를 방지하는 장점이 있습니다.
다음 포스팅에서는 JVM 의 Thread 를 다루겠습니다.
Reference
- Javatpoint, Types of Garbage Collector in Java
- Getting Started with the G1 Garbage Collector
- Baeldung, JVM Garbage Collectors
- Naver D2, Java Garbage Collection
- G1 Garbage Collection (G1 GC)
'Java' 카테고리의 다른 글
| [Java] JVM 알아보기 - (6) Thread, Java Thread Model (0) | 2022.12.05 |
|---|---|
| [Java] JVM 알아보기 - (4) JVM GC, Heap (0) | 2022.11.27 |
| [Java] JVM 알아보기 - (3) JVM Memory Structure (0) | 2022.11.23 |
| [Java] JVM 알아보기 - (2) JVM ClassLoader (0) | 2022.11.17 |
| [Java] JVM 알아보기 - (1) JDK, JRE, JVM (0) | 2022.11.16 |